Tom Breur
3 May 2020
Machine learning is quickly becoming a commodity. As demand for this capacity continues to grow while data scientists remain in high demand and short supply, the next obvious step is pursuing to build predictive models in (largely) automated fashion. Companies like H2O or Datarobot (and many others!) are going out of their way to label automation of these tasks as “Artificial Intelligence”, to my mind a conspicuous inflation of the term. This notion of automating the model building process has gotten so popular that they’ve coined an acronym for it already: AutoML.
Thankfully, the AutoML acronym doesn’t have any explicit reference to artificial intelligence (AI) in it. To my mind, it makes sense to insulate the term AI from gross inflation. As I have written earlier, I would argue that at a minimum you need at least vertical integration to move from automated machine learning to AI. When machine learning (ML) gets embedded into operational execution of the value chain, I think it makes sense (is justifiable) to refer to it as AI. For me, personally, it feels natural to refer to applications of data science without such integration into business decision-making as “old school” ML.
When an applicant signs up online to acquire a credit card, where the back-end solution checks all entries, verifies their plausibility, based on responses along the way chooses “intelligent” follow-on questions, and returns a decision without human intervention, then I think it is fair to refer to this as AI. An online medical diagnostic tool that selects the shortest path of follow-up questions to determine differential diagnoses may be labeled AI. However, when a manager uses marketing automation software to generate a predictive model and score target population for propensity to respond, there are still several steps involved to determine final exclusion criteria, decide on optimal cost/benefit contact strategies, etc. Significant parts in that value chain require human dialogue and deliberation before the campaign gets executed – a straight up example of automated machine learning, if you ask me.
In my blog post “AI: Artificially Inflated” (2017) I refer to “embedded ML” as AI. This definition seems very closely aligned with Marcus & Davis’ (Rebooting AI, 2019) notion of “closed world tasks” and so-called “narrow AI.” These applications bear no resemblance whatsoever to thinking machines, or truly intelligent systems that are capable of human-like reasoning. Nor are they suitable for high stakes problems. They are brittle applications with a tightly defined use case, that may well produce ridiculous and woefully inappropriate outcomes when applied outside of the strictly delineated use cases. Principally different from the science fiction fantasy of Mr Spock (Leonard Nimoy) asking the USS Enterprise board computer his most challenging questions. But just because the current state of AI does not handle real-world and open-ended problems to any degree of reliability, I still don’t think that justifies watering down usage of the term artificial intelligence.
The case for AutoML
Now that we have defined (more or less) a boundary between ML and AI, I’d like to share my thoughts on the state of the profession with regards to AutoML. Lest I sound sceptic or negative, let me begin by saying how much I am in favor of leveraging automation. Reality has been for decades that there was consistently much more demand for data scientists than (qualified) supply. We still haven’t closed that gap between demand and supply of talent. So until then, automation makes all the sense in the world to me (see e.g. my 2017 blog post “Why can’t we close the gap?!?”).
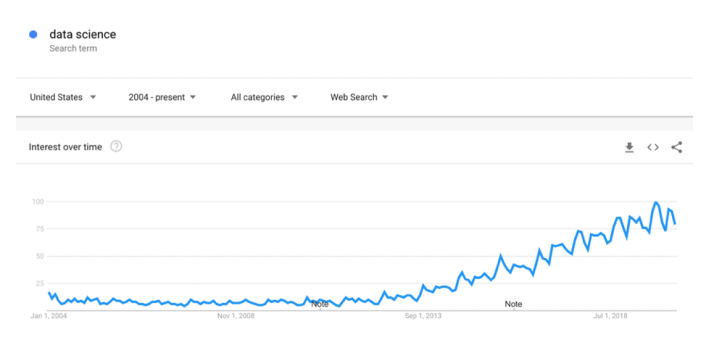
The term data science only came in vogue about 10 years ago, as can be seen below from Google search term popularity:
Historical popularity of search term “data science”
William Cleveland introduced the term “data science” in his paper “An Action Plan for expanding the Technical Areas of the Field of Statistics” (2001), although some would argue that the discipline of data science had been emerging decades before. Notable Tukey (1915-2000) is credited with spurring the development of precursors to data science as we know it today, among others with his book “Exploratory Data Analysis” (1977).
But it wasn’t until DJ Patil and Jeff Hammerbacher (re)introduced the term, and coined the job title data scientist in 2008 that things really took off. In 2012 Tom Davenport and DJ Patil wrote an often quoted article in Harvard Business Review called “Data Scientist: the Sexiest Job in the 21st Century”, and the myth arose that these alchemists could turn dirty data into gold dust. The rest is history, as they say. Another classic hype cycle. At the back end of it, we’re still figuring out how exactly to piece together knowledge of the data (structures), business and domain expertise, together with an amalgam of computer science, math and statistics. Back where Tukey had begun this wonderful journey, so to speak.
Interestingly, and testimony to a lack of progress, KDnuggets has been running a survey on the state of affairs in AutoML titled “When will AutoML replace data scientists (if ever)?” The majority of respondents to their poll believed that AutoML will reach expert level in 5-10 years. What I found even more interesting, was that the same question was asked five years ago, and back then people gave the same answer! So we don’t seem to be getting any closer… No matter how you break down this survey (experience, no experience, industry, etc.) there were hardly any differences: according to the respondents AutoML is still just as far away as it was five years ago.
Looking at the fundamentals, I would argue that ever since computing power has become widely available, and storage costs have dropped in accordance with Moore’s law, there are “natural” opportunities to extract ever more value from these mountains of data. Data in and of themselves represent no value, merely cost. It’s not until you start analyzing them that they materialize their potential value, which obviously is where the data scientists come in. Gil Press made a similar argument in his paper “A Very Short History of Data Science” (2013). As the GoogleTrends graph shows, there are no signs, these developments are changing anytime soon. Whenever tools (like AutoML) can facilitate that value chain, there is an opportunity to create competitive advantage.
Managing the ML value chain
There are two important, but slightly distinct aspects to AutoML: automated modeling, and on the back of this automated model monitoring. The latter is still conspicuously absent as industry surveys continue to highlight. In organizations that leverage data science for predictive modeling (ML), model monitoring is still the exception rather than the rule. If I had to guess, I would estimate that in at most 10% of predictive modeling applications, model monitoring is embedded from the start. Model monitoring is the practice of quantifying how well predictive models hold up their predictive power over time as they are used in production. That 10% is my optimistic guess, btw. In my darker moments of professional despair, it feels more like 1%… And numbers as low as that have been reported in professional surveys that I’ve seen.
There is never a better moment to launch your model monitoring than when you deploy the model. Not a minute or a second later. Tracking the model’s success and decay over time should be built in right from the start. As soon as practical considerations around implementation of the campaign start to distract you, you’re fighting an uphill battle. One important reason to make those choices as you deploy the model (and not afterwards…) is that you want to avoid empirical confounding. How to calculate model effectiveness was the subject of my paper “How to Evaluate Campaign Response (2007)”
The first step is automatic deployment and here is where most, if not all AutoML tools do a great job of incorporating the scoring of models into the workstream. At the end of the model development process, after you have decided on the “final” (best) model, there is a relatively menial and non-value added task of scoring it on the population: determine model predictions for each individual element in the population. The second part of this step is building in control groups as I laid out in my 2007 paper I just mentioned, to ensure you have “clean” test groups that are not subject to experimental confounding.
Model monitoring is when you track over time how response evolves. You normally expect models to degrade, either because the data change, or because reality changes. The ways and reasons for people to respond are subject to a host of dynamics. This will show up in subtle ways, and not uniformly distributed across the population. By employing a sound empirical design of control groups (notice you usually need more than one control group), you can leverage analytics to dive into the subtleties of those changes over time.
Data management
When you build models “automatically”, do you also automatically offset the time? This is one of my pet peeves. After all these years, and so many data scientists getting “hurt” by confounding of causal effects, I am frankly baffled this phenomenon has not made it universally into our basic data science curricula. The time stamp for your predictor variables has to precede the time stamp for the response variable, or else AutoML is not a responsible endeavor. To my mind, all these fancy tools are otherwise just a bigger gun to shoot yourself in the foot with. With corresponding additional damage.
If there is one thing where AutoML could really add value, in my opinion, it isn’t just automatically assembling your dataset, and making sure your automatic model building tool prevents you from causal confounding – it’s riskiest, and most dangerous feature. The data science history road is paved with carcasses along the way, like the neural network that predicted how an airplane could “best” economize on fuel consumption: by flying backwards (…) Needless to say, to enable such a solution requires the appropriate dimensional data model. For reference, see e.g. “The Past and Future of Dimensional Modeling”, (2017).
However, I would like to take this one step further. Only a naive beginner would make the mistake of drawing the predictor and target variable from the same point in time in history. A seasoned data scientist, however, will –quite literally– think ahead. Of course you need to offset these variables in time, but wouldn’t it be great if the AutoML tool allowed you to “simply” specify by how much (how long that time lag should be)? How come that isn’t a standard feature, yet?!? By building in such a feature, you are doubly insured against naïve usage, and, you gain another great option. In an efficient way (albeit computationally intensive), every data scientist could determine how predictive accuracy decays as a function of this time lag. I have laid out the details and technical approach for this in an earlier blogpost “Modeling ‘Time’ for Predictive Models” (2019).
Conclusion
As the field of machine learning evolves and matures, we have accrued quite a few good practices. Many of these merit some kind of standardization, as in: become the default practices. This is easy to “enforce” in a friendly and helpful manner, by automating those parts of the model building process in neat workflows with slick interfaces. I concur that AutoML tools help to save valuable time, and hence increase data scientists’ productivity. Only make your experts look at stuff that requires their attention and judgement, and by all means free them up to focus on elements of model building where they truly add value. There are several verification steps that I’d label menial or boring. Whenever those can be standardized and streamlined – great!
However, as I’ve tried to lay out, I resent labeling this kind of automation as “artificial intelligence. ” But I certainly welcome any and all efforts to leverage the time of data scientists as efficiently as possible. If and when that entire workflow can be (“vertically”) integrated into an application, where non-technical business users are enabled to automatically generate ML models, I am comfortable calling that AI. Note, however, this is really only “narrow AI” as Marcus & Davis (2019) use the term.
Some practices are getting more mature and “settling in”, like looking at model sensitivity and specificity. Making models more explainable is a great idea, even when we should never call this “transparent” – most are emphatically not. My classic example is multiple regression: too many people feel they “understand” regression models, because you can “see” all the regression coefficients. However, unless you know which variables were considered, and how they are associated, the interrelation of regression coefficients is not intuitive at all, I argue. It is simply too hard to get your head around multi-collinearity in a hyperspace when input variables are (almost) always correlated (in practice). You should “read” the value of a Beta weight as change while all other variables are being held constant – but multi-collinearity implies they are not constant, these variables do not change in isolation. All of that being said: the more an AutoML can provide diagnostics and plots to understand how the model operates and why, the better. Those batteries of tests are very convenient output, especially if you don’t have to work so hard to get them (i.e. are part of standard output).
Machine learning modeling has come a long way, and yet there is still plenty to do. With AutoML tools, we are doing a lot to support many repetitive tasks with clever automation. Great! Sadly, this doesn’t hold for the less sexy data grunt work, and need for judicious data modeling. For reasons that escape me, tools have done far less to support that part of the value chain. That omission is even worse, in my opinion, once you realize that your data sources are the unique asset to differentiate yourself with from the competition! I long for the day, when data modeling, and substantive analysis of the meaning and interpretation of idiosyncrasies in the data, gets as much recognition as the machine learning part. I guess data scientists have the sexiest job of the 21st century, but possibly not the most important one, in my opinion – that may well be reserved to data engineers. Or the “next gen” AutoML tools, that will surely be available in 5-10 years…
