Tom Breur
31 August 2019
The job market is “hot”, and data science skills are in high demand. Yet many junior data scientists are struggling to get ahead. How can that be? Is it because every other novice attended the same bootcamp? Or is there maybe something more to it?
The future belongs to data-driven companies, of that I am certain. What are currently the highest valued companies?

Number 1-6 are all (mostly) software companies! The likes of Amazon, Google, Facebook, Uber, etc., all thriving on data, and not -or barely- holding any tangible inventory. The economy has shifted from capital goods to knowledge, that much is clear.
Extrinsic drivers of data science’ popularity
Hal Varian stated in 2009 that “Statistician” would be the sexiest job of the 21st century. Thomas Davenport and DJ Patil latched onto that idea in their 2012 HBR article saying “Data scientist” would be the sexiest job of the 21st century. Since then, the number of job postings in data science has risen sharply. Here are the Google Trends searches for “data scientist” (past 5 years):
“Data Scientist” searches:

Although there probably has been some organic growth in the demand for these skills, this trend mostly illustrates an “inflation” of the term. Positions that used to be reserved for “data analyst” or “business analyst” are now cast as “data scientist” – it cuts both ways. Companies want to be “in” on this new data science trend, and, job postings for a “data scientist” are more likely to draw lots of candidates to apply. Industry veteran Usama Fayyad has some interesting things to say about this dynamic wrt the cost of recruitment in analytics & data science.
This dynamic around job title dilution and inflation drives a vicious loop. Everyone wants to be a part of the Peter Stuyvesant world of data science. Glamorous, reserved for smart, omnipotent alchemists. All these trends led to a stampede for “data science” jobs, followed by an abrupt and brutal realization there is a huge gap between expectation and reality. Lots of grunt work to do, not so much machine learning, or even stats or math.
Although it is always risky to predict these transitions early on, it appears that “data science” may already be past its prime, and that the new magic is coming from AI/ML:
“AI/ML” searches:

Intrinsic drivers of data science’ popularity
As much as publicity and trends may have played into the rise of data science, there undoubtedly is more to it. Gartner championed the so-called “hype cycle”:
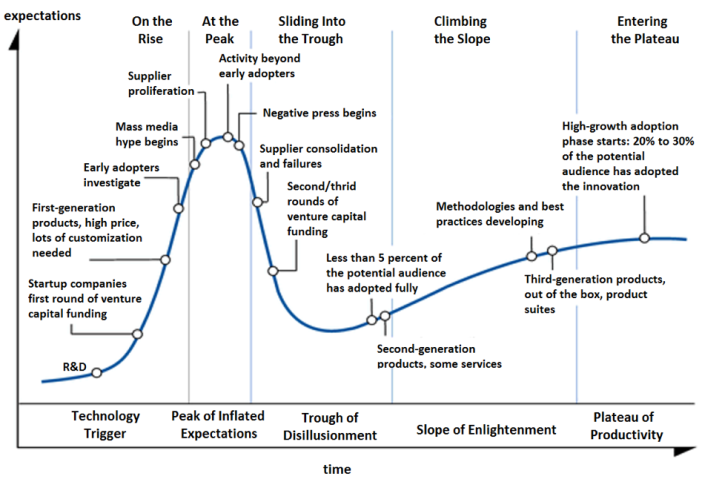
Obviously, VC funding plays a major role in some of these changes, and every transition also leads to new dynamics in the market. Many companies nowadays run their business far more on “numbers” than they ever used to. In part because of evolution in technology that has made all these data available and relatively inexpensive to process, but also because market analysts increasingly expect corporate executives to support their strategic outlook with far richer information than we’ve ever known. I would argue that some of these trends, or hypes, did lead to principled and irreversible change, and hence higher demand for analytics skills in the workplace.
Because corporations are run more “on numbers” than we ever did, opportunities for data scientists have sprouted. What are those leading edge changes in the way we run and evaluate businesses? Here you need to think about “the big questions” – what matters? Given a firm’s business model, how can they leverage analytics to leapfrog the competition? Usually this comes from dramatically reducing costs and losses, driving down lead time (improving business agility), and/or superior efficiency in gaining market share. But always keep in mind: what are you optimizing for? No matter how clever or advanced the algorithm, it only adds value if it advances business goals. I’m reminded of an early application of neural networks in support of airplane fuel efficiency. After many long hours training a neural network, the conclusion was that the optimal solution was the plane flying backwards [sic] – that way you don’t burn fuel, you create it!
Successful data scientists, effective ones, have a knack for surfacing and clarifying business models, and pinpointing opportunities for innovative change. Earlier, I emphasized the distinction between optimizing efficiency versus effectiveness. And difficult as this may seem, especially for junior data scientists, pursuing the hard questions is what matters. In for a dime, in for a dollar. If you are going to do the hard work, you might as well shoot for the stars. As Jay Forrester explained to me at MIT: “big” problems are often just as hard (or easy) to solve as “small” ones, at least with regards to the analysis involved.
How do you get there?
In light of all this context, practically speaking, what can young professionals do to help move their career forward? Recently someone asked me (looking for career advice): “Is there still any use for SQL?” Yes, absolutely! Despite all the Hadoop and NoSQL noise, those SQL skills will likely serve you well for quite some time to come. The principal reason is that your first job is not likely to be as a data scientist, at least not in the stringent definition I have been advocating (see e.g.: “Citizen data scientists” and “Does a data scientist have to code?”). That being said, the odds are they might very well call your job like that.
Data science is a lot about data preparation. In fact, most time is (still) spent getting (access to) data, restructuring it, and cleaning data. Being skillful and quick at these tasks pays huge dividends dividend. To get access to data, chances are you will dig them out of a database, using SQL. Learning to read and write SQL, version it, optimize your queries, are all basic skills. Knowing how databases work, and how you can make queries run faster is incredibly valuable. Somehow, a solid grasp of the basics never goes out of fashion. I’d like to think that going “back to basics”, being adept at pulling and restructuring data efficiently, will always be a core skill. I’m not a big believer of AI-driven “automated” data curation – at least not any time soon. Model optimization, yes. Data modeling and restructuring not so much. Basics are spotting when a model is overfitting the data, being able to reason about it (quantitatively!), and make recommendations what to do about that problem.
Deep learning, we used to ‘just’ call them neural networks, has indeed taken quite a flight. And so has the corresponding hype. If anything, there are way too many people trained in Keras and/or TensorFlow, and far too few people who can frame the crux of decision modeling in plain English and explain the inherent trade-offs to their grandmother. As Richard Feynman said: “If you can’t explain something in simple terms, you don’t understand it.” Do you know what inferences you can, and cannot draw from your data? Can you surface causal relations? Those tend to be the big ticket items.
Data engineering is where the lion’s share of time is spent. Tweaking neural networks not so much. Hence also my bias to old-school SQL, and recommendation for the Python/Pandas framework (see also this already outdated paper from 2017 that I wrote). Being skilled at Python is a hugely valuable skill, and it will also make you more versatile. Knowing Python well buys you options: what seems like a great job today, might change, and other less appealing avenues may seem more attractive in a few years. Solid coding skills, be it in Python or another commonly used language, will serve you well, whichever path you choose. Knowing data pipeline tools is an asset, because entry level people will rarely get to make principled model architecture decisions, and be much more likely to be coding the prerequisite transformations and joins. Be realistic where you stand in your career.
How much experience do you need?
Job postings can be intimidating. Your future employer is certainly allowed to ask for anything. It’s the paradox that people looking to move into a field lack the experience required, and those hiring are reluctant to pay what experienced hire can earn (elsewhere). Once you understand that dynamic, appreciate that all the employer really wants is “reassurance” – hiring is fraught with uncertainty. Asking for people “with experience” is meant to attenuate that uncertainty.
Of course when a job posting requires experience, how can you meet that need as a novice?!? Since “experience” (mostly) serves as a proxy to mitigate the risk of hiring a lemon, think of ways to showcase your abilities, to convince the recruiter you actually can do the job. Good references from internships, project work, and ideally “live” examples. For a (commonly used) tool like Tableau, you can build a public profile and post some dashboards leveraging interesting publicly available datasets. When it comes to coding experience, list your GitHub repository, and have a (genuinely interested) employer check that out. Competitions like Kaggle or DataDotWorld are excellent to hone your skills, learn from others working on the same problems as you, while building up a portfolio that gives an objective and valid reflection of your abilities.
“Experience” isn’t what it used to be. The newer any field, the less likely you will find people with many years of experience. Absent experience from previous jobs, there are still lots of ways that motivated candidates can acquire relevant “experience” before actually landing their first job.
Conclusion
The future is bright for young data savvy professionals. As the price of storage and computing power keeps dropping in accordance with Moore’s Law, more and more data will become available for analysis. There are no signs this trend will slow down any time soon.
Together with the rise in popularity of “data science”, job titles have been subject to inflation: what used to be “data analyst” or “business analyst” jobs, now get advertised as data science. This trend in part obfuscates what the actual work on the job will be like, and also encumbers the hiring process itself by bucketing a much wider variety of applicants together.
For new professionals that are eager to enter this field, it’s a little harder to find your bearings, and (much) less clear what it takes to stand out. Maybe I sound a little jaded, but I’m a firm believer in “back to basics”: doing elementary stuff, and making sure you master it thoroughly. Too many new fads are just that: a fad. Basic SQL and database skills will still carry you pretty far, maybe together with Python/Pandas and a solid grasp of statistics and mastery of predictive modeling.
“Getting started” may seem hard without much (or any…) experience in the workplace, but keep in mind why recruiters are eager to hire talent with experience: it’s a hedge, reassurance. By showing your hands-on skills in publicly accessible form, you can “show ‘m what you got” even if that experience was accrued outside the context of traditional paid work. Besides that, entering modeling competitions like Kaggle is also a lot of fun, with tons of opportunity to learn.
It may be worth noting that in a field that evolves as rapidly as data science, continuous education is a must. Tools and technology are evolving so fast, and knowledge goes stale. If nothing else, by building up your public profile, you highlight experience with contemporary tools. Make learning a habit and grow your portfolio, while at the same time showcasing exactly the attitude you need to become a high potential analytics star.
